这次折腾博客时,我顺手把 Google 收录这件事也接上了。
背景很简单:这个博客以后会越来越偏 AI-first。文章大概率不是我打开 Typora 从头写,而是我给出想法,AI agent 起草,我 review,再发布。既然写作链路要自动化,发布后的索引链路也应该尽量少靠手工记忆。
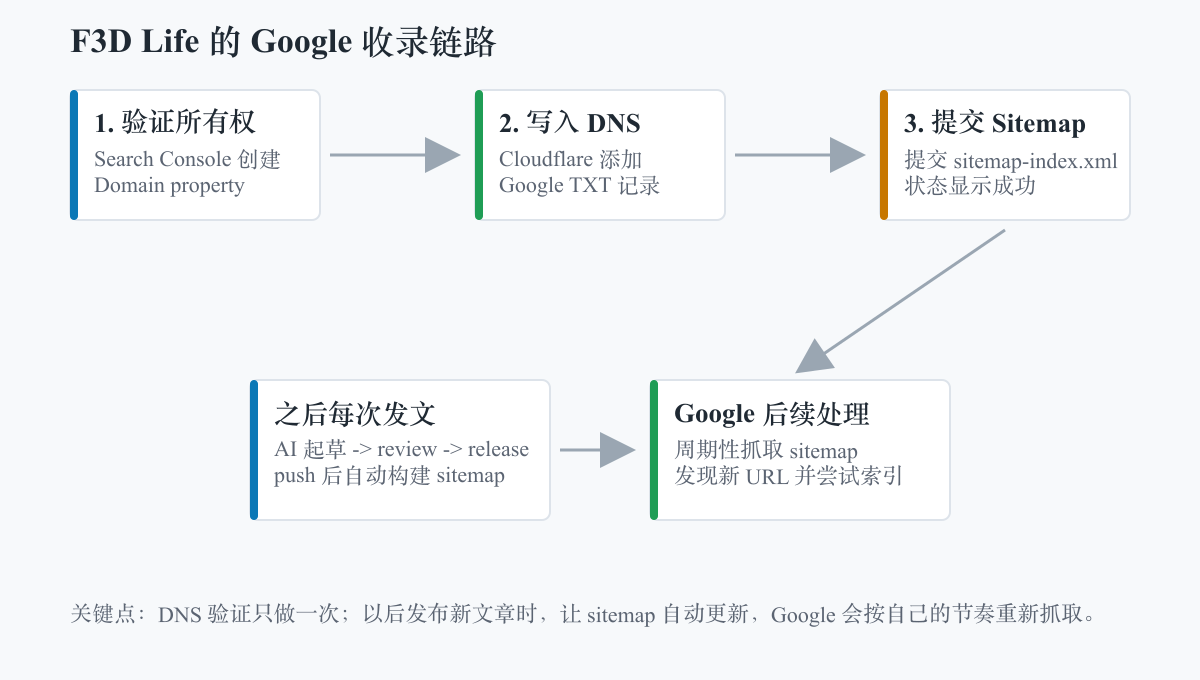
所以这次目标不是“学一下 SEO”,而是把一件确定会重复发生的事变成基础设施:站点能被 Google Search Console 识别,sitemap 能被提交,之后每次发文只要走正常发布流程即可。
问题从哪里来
我之前更关注博客本身:主页不要像模板,about 不要保留框架默认文案,写作规范要写进 AGENTS.md,图片上传要能通过脚本处理,发布也要有明确的 draft/release 边界。
这些改完之后,另一个问题自然冒出来:文章发出去以后,Google 怎么知道它存在?
当然,Google 可以自己发现链接。但对个人博客来说,更稳的方式是:
- 在 Google Search Console 里添加站点。
- 用 DNS 证明这个域名确实属于我。
- 提交 sitemap,让 Google 有一个稳定入口。
- 以后每次发布,让构建产物自动更新 sitemap。
这套流程做一次就够,后面不用每篇文章都重复提交。
核心判断
我最后选的是 Search Console 的 Domain property,也就是网域资源,而不是只验证 https://f3dlife.com/ 这个 URL 前缀。
原因是 Domain property 覆盖面更完整:同一个域名下的 http、https、www、子域名都在一个资源里。缺点是它必须走 DNS 验证,不能只靠 HTML 文件或 meta 标签。
这对我的场景反而刚好合适。域名是在 Cloudflare 管的,本地已经有 Cloudflare API 的环境变量。于是操作路径变成:
- 在 Search Console 添加
f3dlife.com。 - 选择通用 DNS TXT 验证,不把 Cloudflare 账号授权给 Google。
- 通过 Cloudflare API 添加 Google 给出的 TXT 记录。
- 等 DNS 生效后,在 Search Console 点击验证。
- 提交
https://f3dlife.com/sitemap-index.xml。
这里有一个小判断:Search Console 识别到我的域名在 Cloudflare 后,默认建议“授权 Google 访问 Cloudflare”。我没有走这个路径。对我来说,只添加一条 TXT 记录就能完成验证,没有必要扩大授权面。
具体操作
第一步是确认线上博客已经能提供 sitemap。
这个项目用 Astro 构建,线上有:
https://f3dlife.com/sitemap-index.xmlrobots.txt 里也声明了同一个 sitemap:
User-agent: *
Allow: /
Sitemap: https://f3dlife.com/sitemap-index.xml第二步是 Search Console 验证。
Search Console 给出了一条类似下面格式的 TXT 记录:
google-site-verification=...我没有把完整 token 写进文章里。它不是密码,但也没必要公开展示。真正重要的是记录类型和位置:
- 类型:
TXT - 名称:
f3dlife.com - 内容:Google 提供的
google-site-verification=... - TTL:短 TTL 即可
添加后,用公开 DNS 解析器确认 TXT 已经能查到,再回 Search Console 点验证。这个过程比想象中快,Cloudflare 上写完后,公开 DNS 很快就能看到记录。
第三步是提交 sitemap。
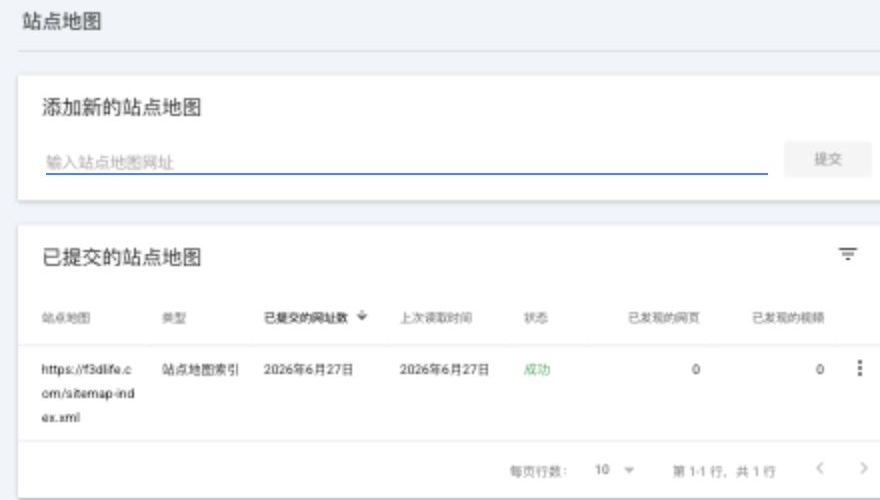
这里踩了一个小坑:我一开始在输入框里填了 sitemap-index.xml,Search Console 提示“站点地图地址无效”。后来提交完整 URL:
https://f3dlife.com/sitemap-index.xml页面就能接受,并且最后状态显示为成功。
这次踩到的坑
这次真正值得记下来的坑有几个。
第一个是 Search Console 的输入格式。对于这个 Domain property,我一开始填相对路径 sitemap-index.xml,页面提示地址无效。最后用完整 URL 才通过:
https://f3dlife.com/sitemap-index.xml第二个是提交后的短暂状态变化。刚提交时页面一度显示“无法抓取”,但从外部看,sitemap-index.xml 和它引用的 sitemap-0.xml 都是 200。刷新后 Search Console 状态变成了“成功”。所以遇到这种情况,第一反应不应该是改代码,而是先验证线上 sitemap 和子 sitemap 是否真的可访问。
第三个是截图脱敏。Search Console 页面顶部会出现账号入口,截图如果直接放进文章,就可能泄露邮箱或头像。我最后只裁了主内容区,保留“sitemap 成功”的证据,不保留账号区域。
第四个是构建环境。这个仓库用的是 npm/package-lock。如果 agent 随手换成 pnpm 或其他包管理器,很容易带来 lockfile、node_modules 和 Pagefind 生成版本的漂移。这个不是文章内容问题,但会污染提交。后来我把它固化成 guardrail:下次提交前自动检查包管理器漂移、Pagefind 版本漂移,以及 Search Console 验证 token 是否误入仓库。
后续每次发文要做什么
接入完成后,以后发文章不需要每次都去 Search Console 点提交。
正常流程应该是:
- AI agent 根据我的想法创建 draft。
- 我 review 内容,确认没有内部笔记、错漏、私密信息。
- 发布前处理图片,保证文章里没有本地图片路径。
- 文章进入 release 状态。
- push 到 GitHub,自动构建部署。
- 构建产物更新 sitemap。
- Google 后续周期性抓取 sitemap,发现新 URL。
这一步里面,Google 的节奏不受我控制。提交 sitemap 不等于立刻收录,更不等于立刻有排名。它只是告诉 Google:这里有一份结构化 URL 列表,可以来抓。
如果某篇文章特别重要,可以在 Search Console 的“网址检查”里输入文章 URL,然后请求编入索引。但这应该是例外,不应该变成每次发布都依赖的手工动作。
我的实践/例子
这次最有价值的不是“把 Google 接上了”,而是把边界想清楚了:
- 站点所有权验证属于一次性基础设施。
- sitemap 提交属于站点级配置,不是每篇文章的发布动作。
- AI agent 可以处理重复性的检查、上传、构建和验证。
- 最终是否发布,仍然必须由我明确批准。
这也解释了为什么我会先写 AGENTS.md 和发布脚本,再处理 Google 收录。
如果没有这些规则,AI 很容易把“帮我写一篇”理解成“顺手发了”。而对个人博客来说,这个边界很重要。草稿可以快,发布要慢一点。
还不确定的地方
目前 Search Console 已经能看到 sitemap,并显示成功。但 Google 什么时候抓取新文章、哪些页面最终进入索引、搜索结果里如何展示,这些都需要时间。
我不会为了这个阶段做太多所谓 SEO 优化。更值得先做的是:
- 保持标题具体。
- description 写成人能看懂的一句话。
- sitemap 稳定更新。
- 页面不要有模板残留和无意义内容。
- 文章真的解决一个问题。
这些比堆关键词更适合这个博客。
小结
这次接入 Google 收录,表面上是 Search Console、Cloudflare DNS 和 sitemap 三件事。
但对我来说,它其实是 AI-first blog 的一块基础设施:以后我负责判断和 review,AI agent 负责把流程跑稳。文章发布之后,站点会自然更新 sitemap,Google 会按它自己的节奏来抓。
这就够了。写博客不该被发布杂务拖住,但也不能因为自动化而失控。